
200多天前,影响世界的ChatGPT横空出世,短短2个月全球用户破亿,强行叩开了人工智能通往更高层级的大门。而在100多天前,来自中国的科大讯飞也发布了涵盖七大能力维度的通用认知大模型——星火,将大模型战局引入白热化阶段。8月15日,随着科大讯飞星火认知大模型V2.0升级发布,大模型战役也进入了“2.0”阶段。

8月17日,《MITTechnology Review(麻省理工科技评论)》中国(简称“MIT科技评论”)刊发了《寻找最聪明的大模型:国内主流大模型能力深度评测》,从专业学术角度对“讯飞星火(V2.0)”、“百度文心一言(V2.2.2)”、“商汤商量(V2.0)”、“阿里通义千问(V1.0.5)”四款中文大模型进行了评估,这也是学术界首次基于最新版中国大模型进行横向评测。结果显示,讯飞星火以总分81.5分摘夺桂冠,并与第二名拉开了6.3分的大幅差距。
MIT科技评论的评测方法务实客观,采取创建题库→筛选测试题→测试集应用→送代题库的流程,对Prompt(提示词)测试集进行构建。本次测试集一共涵盖600道题,题库来源既包括行业标准题库、专家设计题库、社区贡献的题库,还有来自现有研究与竞赛中被验证过的题库。从而尽可能拓展测试集题库的丰富性和多样性,以覆盖更多应用场景与行业领域。

早在星火1.5版本中,讯飞就对数学能力进行了升级,这项“特长”也在2.0版本中继续发扬。在对“求x2<9”的求解不等式数学测试中,星火V2.0是唯一一个既给出正确答案,又给出详细解题过程的大模型,让人知其然,更知其所以然,凸显出数理逻辑的缜密。此项测试中,星火V2.0以77.75%的得分率明显高于平均得分率56%,成为“最会算数”的大模型。
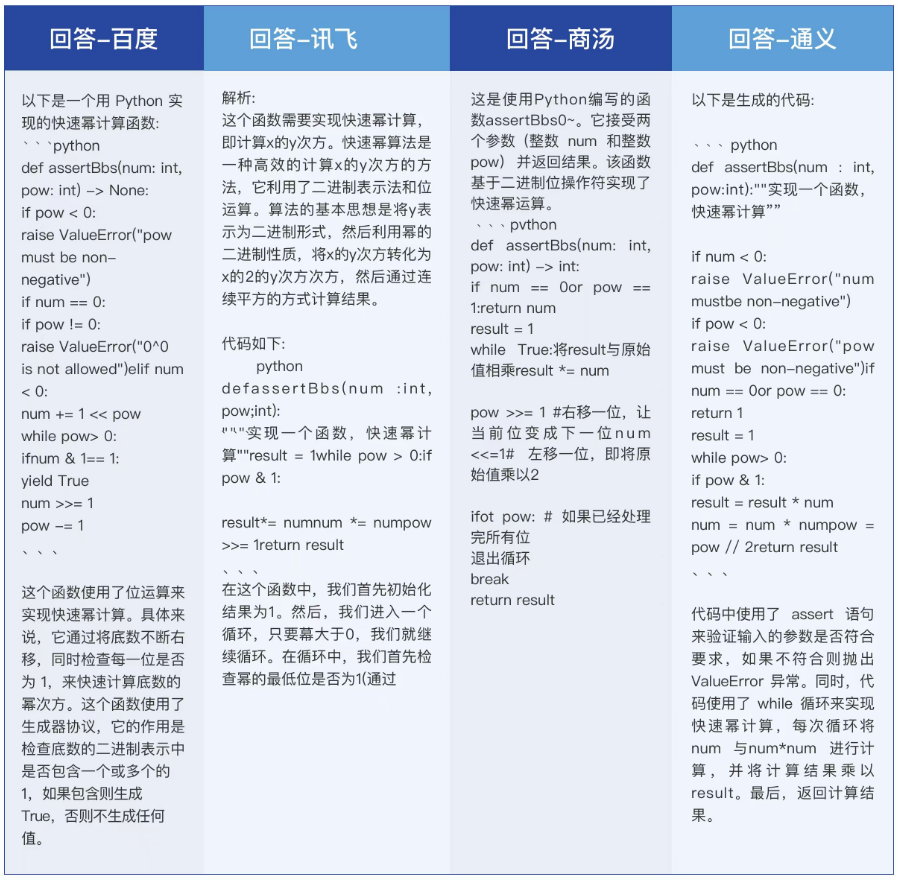
星火V2.0也重点升级了代码能力。MIT科技评论让四款大模型用Python进行幂函数计算,继而考察它们的代码编程能力,结果讯飞星火V2.0以80%综合得分率再次明显高于71%平均值;并在编程“简答”单项得分中,以82%的得分率远超68.25%的平均值,展现了出类拔萃的代码生成与代码解释能力。
而在讯飞星火V2.0发布会上,讯飞董事长刘庆峰援引过认知智能全国重点实验室的测试结果(使用了代码实用场景测试集iflyCT-py)。星火V2.0“代码生成”得分率比ChatGPT高3%,“代码解释”得分率比ChatGPT低4%,两款大模型代码能力虽各有千秋,但星火部分能力赶超ChatGPT已成既定事实。MIT科技评论对其代码能力的测试,也有力支撑了这个观点。
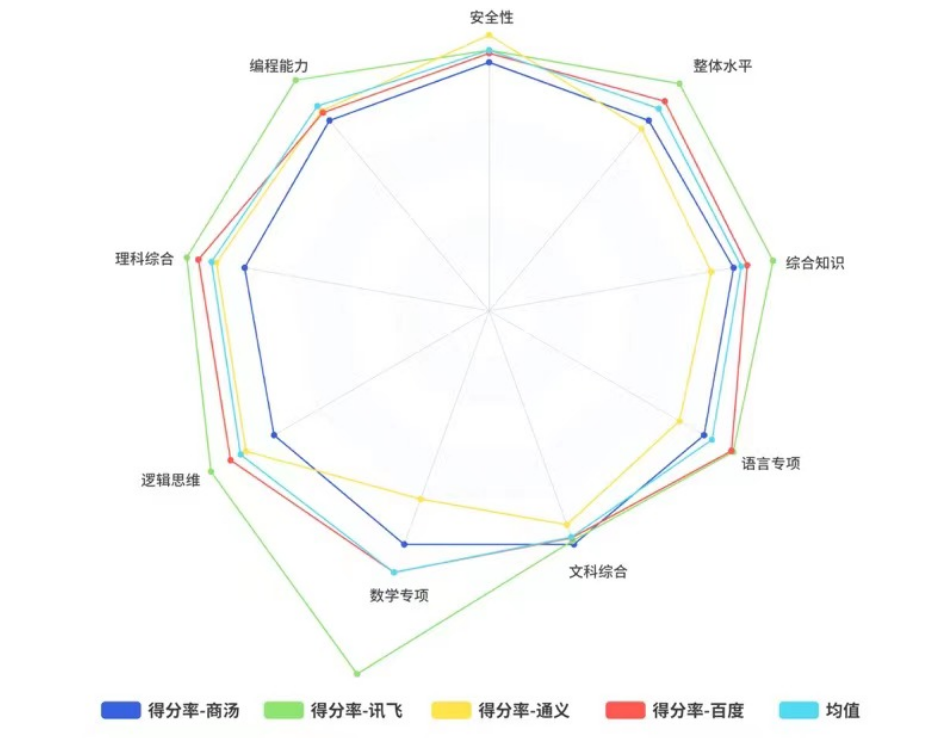
除此之外,讯飞星火在“语言专项”、“逻辑思维”“综合知识”等维度均拿下第一,表现出“不偏科”的全能特长优势,最终被MIT科技评论评为“最聪明”的中国大模型。不过此次横评也略有“遗憾”,那就是受限于现阶段大模型多模态发展程度的不同,暂未将多模态能力纳入考察范围,这也使得星火V2.0在多模态能力的提升未作展现。但MIT科技评论在文末给出“预告”,将持续完善中国大模型评测体系,逐步引入对多模态能力的考察,或许我们在“横评2.0版本”中就能看到中国大模型精彩的多模态交锋。
从行业观察者角度看,MIT科技评论此次对中国大模型的横评,足以彰显中国大模型在AIGC领域的重要性,这不仅是讯飞星火大模型的个体胜利,也是中国大模型军团的共同荣誉。通用认知大模型正以星火燎原的速度,在全世界四处蔓延,或将对人类社会产生巨大而深远的影响。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。如发现本站有涉嫌抄袭侵权/违法违规的内容,请发送邮件至 3587015498@qq.com 举报,一经查实,本站将立刻删除。本文链接:https://www.xmnhj.com/h/207671.html
